
[!NOTE] 本稿は査読前のプレプリント(arXiv: 2512.06727)に基づいています。
これは何の話?
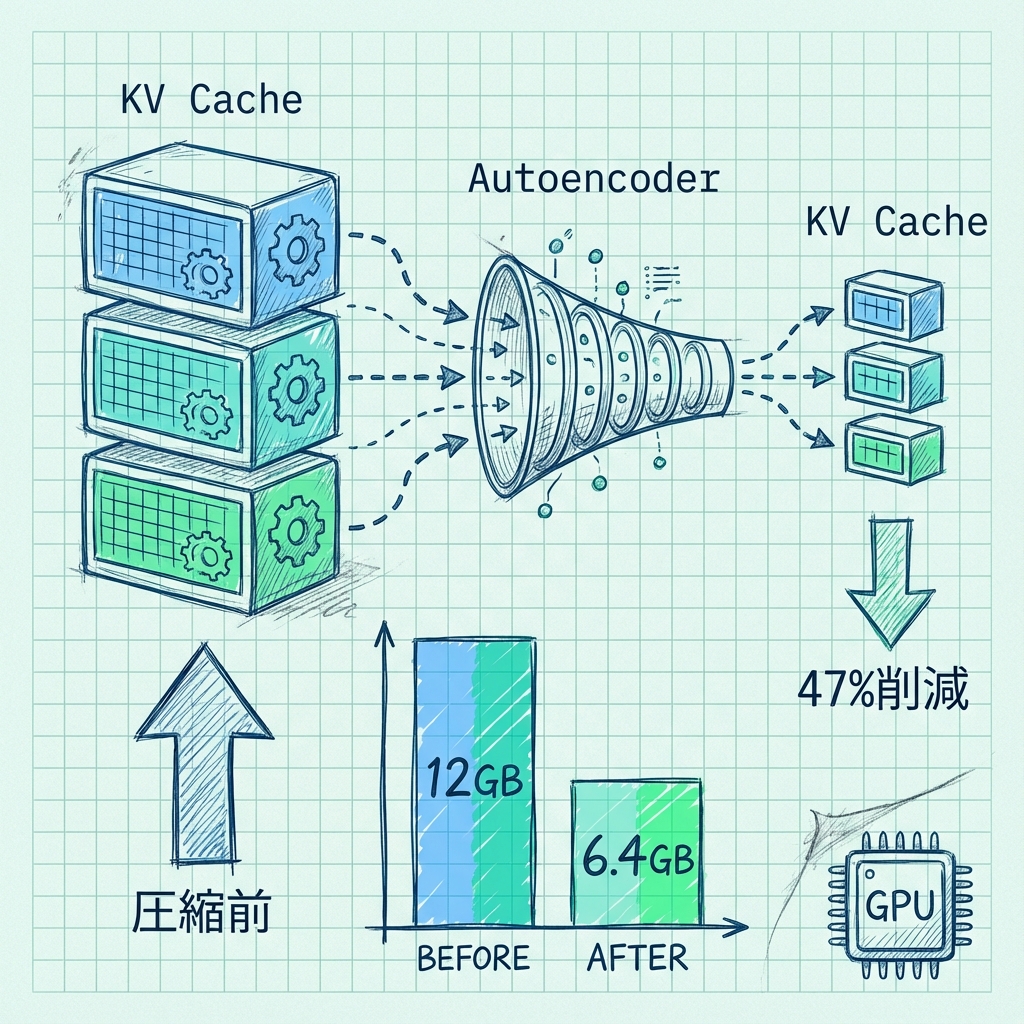
LLMの推論時にメモリを圧迫する「KVキャッシュ」の問題を解決する新手法です。本論文では、オートエンコーダによる圧縮と隣接レイヤー間でのKV再利用を組み合わせた「KV-CAR」フレームワークを提案しています。
対象読者は、LLMの推論コスト削減やオンプレミス展開に取り組むMLエンジニアです。KVキャッシュはシーケンス長と埋め込み次元に比例して増大し、モデル本体を超えるメモリを消費することもあるため、効率化は実運用上の重要課題です。
何がわかったか
KV-CARは2つの技術を組み合わせています。第一に、軽量オートエンコーダがKeyとValueのテンソルを埋め込み次元に沿って圧縮し、キャッシュ保存前にコンパクト化します。第二に、類似度ベースの再利用機構が隣接レイヤー間で共通性の高いKVテンソルを特定し、冗長な保存を省きます。
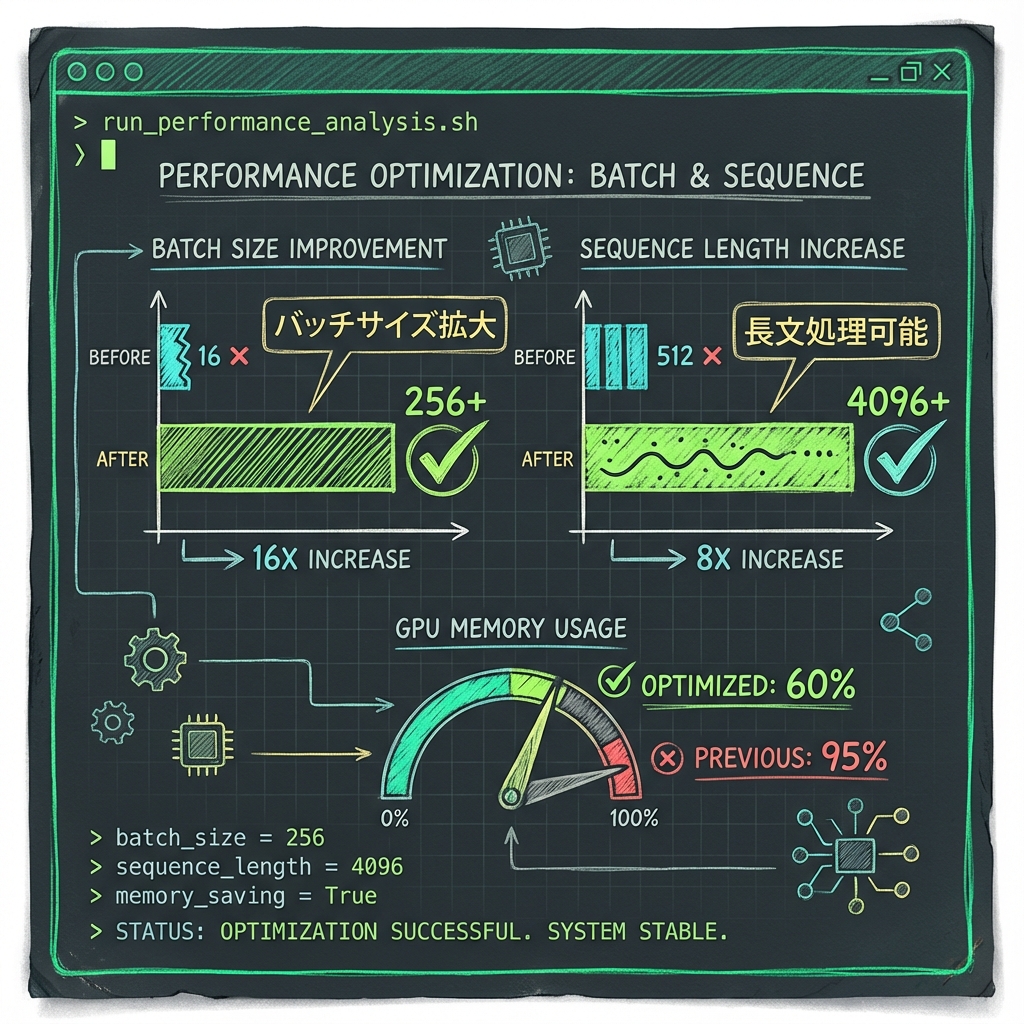
GPT-2とTinyLLaMAをWikitext、C4、PIQA、Winograndeで評価した結果、KV-CARは最大47.85%のKVキャッシュメモリ削減を達成し、パープレキシティとゼロショット精度への影響は最小限でした。NVIDIA A40での実測では、削減されたメモリがそのまま長シーケンス長と大バッチサイズの実現に直結することが確認されています。
他とどう違うのか
既存のKVキャッシュ削減手法は、主にトークン単位の剪定や量子化に依存していました。KV-CARの特徴は、埋め込み次元方向の圧縮と構造的な再利用を組み合わせ、Transformerアーキテクチャ自体を変更せずに適用できる点です。
これにより、既存のモデルに後付けで導入しやすく、他の最適化手法(量子化など)との併用も可能です。
なぜこれが重要か
KVキャッシュのメモリ制約は、長文コンテキスト処理やリアルタイム応答が求められるユースケースで大きなボトルネックになります。47%近いメモリ削減は、同一ハードウェアでより多くの同時リクエストを処理できることを意味し、推論コストの直接的な削減につながります。
特にエッジデバイスやコスト制約のある環境でのLLM展開において、本手法は実用的な選択肢を広げます。
未来の展開・戦略性
KV-CARは現時点でGPT-2やTinyLLaMAといった比較的小規模なモデルで検証されていますが、同じアプローチがLlama 3やGemini規模のモデルに適用可能かが次の焦点です。
また、オートエンコーダの学習コストと圧縮率のトレードオフ、リアルタイムエンコード/デコードのレイテンシ影響も、大規模展開に向けた検討項目です。
どう考え、どう動くか
例えば、オンプレミスでLLMを運用しているチームが長文コンテキスト対応を検討する場合、まずKV-CARのオートエンコーダをTinyLLaMAで追試し、自社ユースケースでの精度劣化を測定するアプローチが考えられます。
- 論文のGitHubリポジトリ(公開されている場合)をフォークし、自社評価データで再現実験を行う。
- 既存の量子化手法と組み合わせた場合の複合効果を検証する。
- A40以外のGPU(例:RTX 4090やL4)でのベンチマークを取り、コスト対効果を比較する。
次の一歩:
- 今日やること:論文のMethodセクションを確認し、オートエンコーダのアーキテクチャ詳細を把握する。
- 今週やること:自社推論パイプラインのKVキャッシュ使用量を計測し、47%削減時のインパクトを試算する。
限界と未確定
- 検証モデルがGPT-2とTinyLLaMAに限定されており、大規模モデルでの性能は未検証。スケーラビリティは別途確認が必要。
- オートエンコーダの事前学習コストやモデル固有の調整の必要性が論文内で詳述されていない。著者へのコンタクトまたはコード確認が次のステップ。
- リアルタイム推論時のエンコード/デコードレイテンシへの影響は、本研究の範囲では深く議論されていない。
用語ミニ解説
- LLM推論時に過去のKey/Valueベクトルを保存し再計算を省く仕組みです。(KVキャッシュ / KV Cache)
- データを低次元に圧縮し復元するニューラルネットワークです。(オートエンコーダ / Autoencoder)
出典と日付
arXiv(公開日:2025-12-13):https://arxiv.org/abs/2512.06727





